Мера tf-idf и косинусная мера сходства
Введение векторных операций позволяет нам говорить о методах гораздо более компактно. Здесь мы рассматриваем конкретный пример: установление сходства документов – инструмент, общеупотребительный в Web-рекламе. Одна из областей использования – выявление подделок. Когда у многих разных рекламодателей имеются ссылки на очень похожие страницы, обычно, на самом деле, все они являются одной группой злоумышленников, и очень вероятно использование для оплаты украденых кредитных карт. Поэтому разумным подходом является обследование исходящих ссылок рекламодателей и поиск похожих документов.
Распространенная метрика сходства документов tf-idf включает три или четыре шага, которые все легко распределяются и хорошо сводятся к методам SQL. Во-первых, необходимо создать триплеты (document, term, count). Затем с использованием простых SQL-запросов с GROUP BY вычисляются маргиналы по document и term. После этого исходные триплеты можно расширить оценкой tf-idf по каждому измерению (т.е. для каждого слова результирующего словаря) путем соединения триплетов с маргиналами данного документа и отделения счетчика числа документов от счетчика числа терминов. На основе этого для каждых двух документов вычисляется косинусная мера сходства, и получается стандартная метрика "расстояния".
Более точно, хорошо известно, что для двух векторов весов терминов x и y косинусное сходство θ задается соотношением θ =
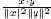
SELECT a1.row_id AS document_i, a2.row_id AS document_j, (a1.row_v * a2.row_v) / ((a1.row_v * a1.row_v) * (a2.row_v * a2.row_v)) AS theta FROM A AS a1, A AS a2 WHERE a1.row_id > a2.row_id
Для любого аналитика, привыкшего к скриптовой среде SAS или R, эта формулировка совершенно приемлема. Кроме того, работа по распределению объектов и определению операций выполняется DBA. Если объекты и операции становятся более сложными, возрастают преимушества наличия предопределенных операций. С практической точки зрения мы превращаем систему баз данных из простой системы выборки данных в интерактивную среду аналитического программирования.
